Other Import Options
Other import options are:
- Zotero Synchronisation
- Index Multimedia
- Harvest Emails
- Import Hyperlinks
- Import KML
- Multi-File Upload
Zotero Synchronisation
Heurist provides the following functions and capabilities for importing bibliographic data:
- Automatic identification and disambiguation of imported bibliographic types.
- Authors stored as person records allowing rich complementary data.
- Series, Journals, Publishers stored as separate records to eliminate data redundancy.
- Pre-defined domain profiles with collections of useful references, tags and searches.
Before you Begin
If you have not done so, enter access details for your Zotero library via: Administration | Properties | Locations.
Index Multimedia
The option reads FieldHelper XML manifest files (from the specified folders and their descendants) and writes the metadata as records in the current database, with pointers back to the files described by the manifests. If no manifests exist, they are created (and can be read by FieldHelper). New files are added to the existing manifests. If the current database already contains data, new records are appended (existing records are unaffected).
About FieldHelper
FieldHelper provides a unique drag-and-tag interface for creating metadata for multimedia files (including spatial metadata) within a framework based on geographic location and time of collection, and to generate XML repository packages without programming. It provides a robust methodology to maintain XML manifests for each folder and sub-folder indexed. The FieldHelper web page and download files are available here.
The Index Multimedia option allows you to import a series of FieldHelper Manifests (compatible with the FieldHelper metadata editor) and associated files stored in a special folder on the Heurist server.
Scanned files include: (jpg, png, gif tif, tiff, wmv, doc, docx, xls, xlsx, txt, rtf, xml, xsl, xslt, mpg, mpeg, mov, mp3, mp4, qt, wmd, avi, kml, sid, ecw, mp3, mid, midi, evo, csv, tab, wav, cda, wmz, wms, aif, aiff).
Note. If no manifests exist, they are created (and can be read by FieldHelper). New files are added to the existing manifests. The current database may already contain data; new records are appended, existing records are unaffected.
Before you begin
- If the database has not been registered with the Heurist Master Index, you will need to do so (only the creator of the database, user #2, can do this). See Register.
- The folders to be indexed must be writeable by the PHP system; normally they should be owned by Apache or www-data (as appropriate). Normally they should be owned by 'nobody'.
- Files will need to be uploaded to the server via direct access to the server or through Import | Multi-file upload.
- Heurist sets the location of the media folders (Filestore) by default. The Filestore folder is located on the server on which Heurist is running. You may need to consult with your system Administrator to find out the location of the database Filestore and to get access to copy folders to it.
- To view or specify another location for the media folder, go to Database | Properties | Locations. In the Additional folder(s) containing files for indexing field, enter the folder address. To set the extensions to scan, update the File extensions to index field.
Import multimedia files
Drop the folder or folders of files to be imported into the Filestore media folder. Select Database | Import | Index Multimedia.
The Filestore media folder location is indicated in the Folders to Scan field. To specify another location for the media folder, or update the file extensions to index, click Click here to set media folders.
Click Continue. Heurist will scan the folder(s) designated, and any child folders, and add any files discovered to the database as Digital Media Objects. The file path, name, extension, size, MD5 checksum and date are extracted.
In addition, if metadata has been created for the files using FieldHelper, this metadata (including geographic location) will be imported into the record.
Error messages
You may get error (red) and warning messages, such as:
- Folder is not writeable. Check permissions. (Error) In this case your System Administrator will need to change the Ownership of the folder.
- 485 entries in manifest ignored. (Warning) The indicated number of entries ignored is simply the number of files which were previously imported and are therefore ignored by this import.
Harvest Emails
Database | Harvest Emails
This feature allows you to set up an email account to which users of the database can forward emails they receive or copy emails that they send, in order to have them archived in the Heurist database. It imports emails received from specific email addresses (set in each user's profile) via a specified email server supporting IMAP.
Heurist will connect to an email server using the login details stored in the database properties (sysIdentification table) and retrieve emails received from specific email addresses (set in each user's profile). The emails are dissected and used to create Heurist records owned by that user. The email server must support IMAP.
Note. You must be a member the Database Owners group for this database.
Set up the following configurations:
- Configure connection to IMAP mail server (per-database). Enter details for an email account to which users of the database can forward emails they receive or copy emails that they send, in order to have them archived in the Heurist database. Click Save then Back to Import. See also Database | Properties | Locations.
- Configure email addresses to be harvested. In the Optional information | Incoming email addresses section, enter one or more address (separated by commas). When ready, click Harvest Email from IMAP Server. See also Profile | My User Info.
Import Hyperlinks
Import / Import Hyperlinks
(See also Bookmarklet.)
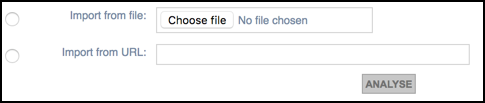
To import the file, use either of the following options:
- Import from File. You can import hyperlinks from a HTML web page, to be added as new bookmarked records (e.g. to capture a page found through Google containing a set of resources of interest). You can specify which hyperlinks to import. Use the Choose File button to identify the bookmark or web page file.
To export a bookmarks file from your browser, either:
- Export browser bookmarks as a HTML file. Select the relevant bookmark folder and select the appropriate Export option. For example, in Chrome: Select Bookmarks | Bookmarks Manager. Select the relevant folder. Select Build | Export bookmarks to HTML file. In most cases, the default output file is: bookmarks.html.
- Export a HTML page. Open the relevant page in your browser, and select the Save As HTML option. For example, in Chrome: Right-click and select Save As | Webpage HTML Only.
- Import from URL. You can import bookmarks saved as a HTML file from your web browser. Enter or paste the URL in the field.
Click Analysis. All captured links in the page or file are displayed:
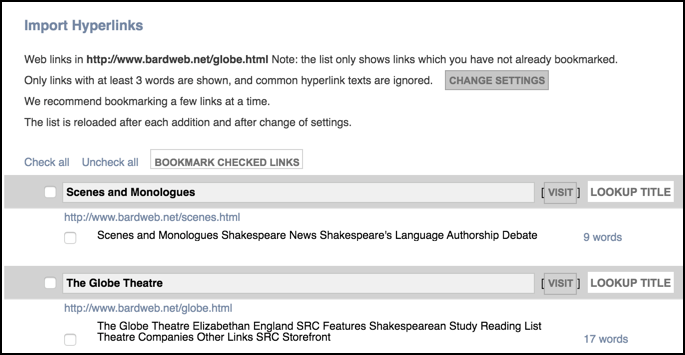
(See Change Settings below to modify the capture criteria.)
Select the checkboxes for one or more links (or Check All to import all links). Click Bookmark Checked Links.
On the Manage Tags page enter or select at least one tag and click Save. The selected links are saved as records, and you are returned to the Import Hyperlinks page. (if a record already exists it is not saved, but will be highlighted in the list.)
Note. The title of the saved records are hyperlinks, underlined to indicate that clicking them will open the linked page.
Change Settings
Use the Change Settings option to filter particular hyperlinks or ignore (short) hyperlinks of a certain length.
When importing web links from a HTML file or web page, Heurist applies a set of filters to remove any short or repetitive functional web links such as: Similar pages, Terms of Service etc. You can also limit the list to titles longer than a specified number of words, since one or two word hyperlinks are generally related to page function rather than useful information.
Change the show only hyperlinks number of word requirement (the default is at least five words). Add any hyperlink text to ignore and click Add. Repeat as required. To remove an entry, type it in and click Remove.
Click Done. The Import Hyperlinks page is refreshed based on your new settings.
Import KML
Database | Import | KML

KML (Keyhole Markup Language) is a file format used to display geographic data in an Earth browser such as Google Earth, Google Maps, and Google Maps for mobile. KML uses a tag-based structure with nested elements and attributes and is based on the XML standard. All tags are case-sensitive and must be appear exactly as they are listed in the KML Reference. The Reference indicates which tags are optional. Within a given element, tags must appear in the order shown in the Reference. For additional details, go here.
Heurist will recognise the KML format and process the file, and prompt you for a record type. All records created by a single KML import will have the same record type.
Select Choose File and browse to select a KML file to import. Click Continue. A summary of records to be imported is shown. When ready, click Continue. Heurist will recognise the KML format and process the file, and prompt you for a record type.

Select the record type and click Continue.
Note. All records created by a single KML import have the same record type.
KML Field Definitions
This table shows how the data is mapped into Heurist; it lists the KML tags that Heurist recognises as record details, and the bibliographic data fields that they are imported to.
Note. Contact Heurist for the full list of KML Field Definitions for the XML file to determine how the data is mapped into Heurist.
Heurist attempts to import each <Placemark> as a separate record.
KML tag |
Heurist detail field |
<name> |
Title (detail type #160) |
<address> <AddressDetails> |
Location (#181) |
<phoneNumber> |
Contact information (#309) |
<TimeSpan><begin> |
Start Date (#177) |
<TimeSpan><end> |
End Date (#178) |
<TimeStamp><when> |
Date (#166) |
<Region> <Point> <LineString> <LinearRing> <Polygon> <MultiGeometry> |
Geographic object (#230) |
<Snippet> <description> <Metadata> |
Shared scratchpad |
It is possible to specify Heurist-formatted data in HXTBL format between KML's <Metadata> tags. For example:
...
<Placemark>
...
<Metadata>
<detail name="Name of organisation" id="160">
Archaeological Computing Laboratory
</detail>
<detail name="Organisation type" id="203">
Laboratory
</detail>
</Metadata>
...
</Placemark>
...
Heurist will add fields of type #160 (Title) and type #203 (Organisation Type) to the record corresponding to this <Placemark>.
Multi-File Upload
Import | Multi-File Upload
(Not yet fully implemented.)
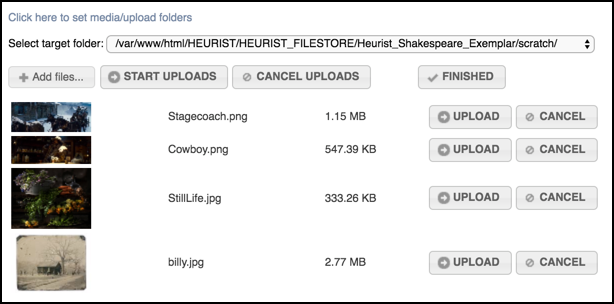
The Multi-File Upload option allows you to upload multiple files to your database's scratch space and delete files from that space. You might decide to do this for a number of reasons prior to importing data from the files or running the in-situ import of images (Index MultiMedia).
Note. This feature is restricted to database Owners/Administrators to reduce the risk of other users filling the database with unwanted material.
If you wish to upload files to a directory other than the scratch space, select Click here to set media/upload folders and define the folders (in Manage | Database | Properties | Additional Folders for indexing. You may also add additional file extensions here. Click Back to Import to close this screen.
To start uploading, use the Add File button to select and add one or more files.
To upload all selected files, click Start Upload. Or to upload an individual file, click Upload for that file.
The file(s) are uploaded to the designated filestore. Click Finished to clear the items, and continue.
Created with the Personal Edition of HelpNDoc: Free Kindle producer